

L'élément <FONT>, surtout lorsqu'il est accompagné de son
attribut FACE, est un des pires fléaux à s'être abattus sur le Web
ces derniers temps. Même s'il est possible d'utiliser l'élément
<FONT> à bon escient, la plupart de ses applications sont
déconseillées, tel qu'en témoigne cet article consacré à
<FONT>. L'article signale les effets pervers qui peuvent découler
de l'utilisation de <FONT FACE>, et ce même si on se limite à
l'utiliser tel que conçu (à savoir contrôler la mise en forme), mais n'aborde
pas les problèmes que son utilisation peut engendrer dans le cas de documents
multilingues ; c'est précisément de cet aspect que nous allons discuter
ici.
Le texte est normalement transmis sur le Web — de même dans les autres applications Internet — comme une séquence de caractères codés. En clair, ceci signifie qu'à chaque code correspond, par convention, un seul et unique caractère, lequel est interprété et affiché par l'application réceptrice. Il existe un certain nombre de ces codes de caractères, reprenant un répertoire de caractères correspondant normalement à un système d'écriture.
Le fait est que si vous utilisez <FONT FACE> et que vous
spécifiez une police pour une écriture différente, vous mentez au fureteur sur
l'identité réelle des caractères qui sont censés être identifiés par les codes
sous-jacents de votre ordinateur. Si vous tapez
<FONT FACE="police_grecque">xyqdwo</FONT>,
vous obtiendrez, à coup
sûr, des caractères grecs mais ce n'est pas la bonne façon de coder du
texte grec.
Plusieurs problèmes découlent de la mise en œuvre de l'approche décrite ci-dessus. Le problème le plus évident est que si l'utilisateur qui parcourt votre page ne dispose pas de la police exacte que vous avez spécifiée, il verra le texte dans la police par défaut de son fureteur, qui ne sera pas une police grecque (à moins qu'il ne soit grec lui-même, bien entendu !), alors qu'il est possible qu'une police grecque tout à fait convenable soit présente sur son système, laquelle aurait pu être utilisée si seulement vous aviez codé le texte convenablement.
Cet exemple propulse au premier plan le problème de la prolifération des
polices : les caractères (ou plus précisément les glyphes) d'une police sont
numérotés, l'ensemble des combinaisons glyphe–numéro formant ce qu'il est
convenu d'appeler le codage de la police. Or, une langue ou une écriture données
peuvent se concrétiser en une grande variété de codages. Si vous utilisez une
correspondance de polices simpliste (et c'est ce que fait <FONT
FACE>) pour coder votre texte, vous êtes à la merci du codage propre à
la police choisie. Et si le voisin d'en face choisit une autre police, codée
différemment, vous n'avez d'autre choix que d'installer sa
police pour afficher ses pages. Puis, cet autre type utilise une autre police,
et cet autre webmestre en herbe utilise sa propre police, etc. Votre disque se
remplit de polices de caractères ? Rien d'étonnant ! Et nous n'avons
même pas abordé le sujet des styles, cette prolifération n'est que pure
redondance.
Avec pour conséquence la fragmentation du cyberespace en un ensemble de zones exclusives (à moins que vous ne disposiez de toutes les bonnes polices), ce qui ne correspond pas précisément à l'esprit du Web ! Imaginez seulement le fouillis qui résulterait de l'utilisation de cinq saveurs d'ASCII, toutes incompatibles, et qui obligeraient les utilisateurs à de pénibles conversions de l'une à l'autre, après avoir deviné l'essence de la saveur en cause.
Et qu'en est-il de la recherche de ce texte grec (ou autre) au moyen de votre moteur de recherche préféré ? Oubliez ça ! À moins de savoir exactement quelle police l'auteur a utilisée, et ce a priori, afin d'être en mesure de spécifier les faux caractères « corrects » au moteur de recherche. Même l'utilisation de la fonction de recherche textuelle de votre fureteur pour repérer un mot dans la page courante a toutes les chances de donner un résultat non satisfaisant.
De la même façon, une liste de mots grecs (ou autres, évidemment) codés par
mappage de police ne pourra être triée correctement. En fait, tout traitement du
texte devient pratiquement impossible avec cette technique de codage. Si vous
créez des pages Web — et ça ne peut qu'être le cas si vous
utilisez <FONT FACE> — vous utilisez sûrement
souvent la fonction couper-coller. Bonne chance si le texte coupé n'utilise pas
la même police que le document où vous voulez le coller ! Il ne vous reste
plus qu'à retaper le texte en entier ; mais la disposition du clavier
n'est-elle pas tributaire de la police ?
La raison d'être d'Internet est la communication. Le Web utilise le langage
HTML comme format commun de documents mais qu'en est-il des autres moyens de
communication ? L'HTML n'est généralement pas disponible, et vous serez
forcés d'oublier l'HTMLisant <FONT FACE>. Le temps est venu
d'envisager l'utilisation d'un véritable codage de caractères qui sera capable
de porter vos écrits en texte simple, peu importe le médium (courrier, inforums,
causerie, etc.). HTML est censé être un moyen d'enrichir le texte au
moyen d'hyperliens et d'autres embellissements. Pour ce faire, il faut tout
d'abord que le texte sous-jacent ait son sens avant que n'entrent en jeu les
balises HTML, ce que l'utilisation de <FONT FACE> empêche
précisément.
La situation est encore plus épouvantable lorsqu'on a affaire à une écriture
complexe. Mais qu'est-ce au juste qu'une écriture complexe ? Bien, disons
tout simplement qu'une écriture « simple » est caractérisée par une
relation biunivoque entre caractères et glyphes ; toutes les autres
écritures sont réputées complexes. Les écritures latine, cyrillique et chinoise
sont des écritures dites simples. Le chinois, simple ? Oui, dans le sens
que les caractères et les glyphes chinois sont en correspondance biunivoque,
mais leur traitement informatisé est complexe à cause du très grand nombre de
caractères ; un octet ne suffit pas à les coder tous (et de loin !),
il faut recourir à deux et même à trois octets et <FONT FACE>
ne fonctionne tout simplement pas. Même chose pour le japonais et le coréen.
Dans quelques écritures complexes, le glyphe change en fonction de la position du caractère dans le mot (initiale, médiale, finale or isolée) ; c'est le cas en arabe. Dans d'autres cas, il existe des ligatures obligatoires qui ont pour effet de combiner deux ou plusieurs caractères en un seul glyphe, comme en dévanâgarî (utilisé par la langue hindi). Ou alors un caractère est affiché en deux glyphes de part et d'autre du glyphe d'un autre caractère, par exemple en tamoul.
Également :
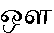 tamoul peut être la voyelle (AU) ou la voyelle
tamoul peut être la voyelle (AU) ou la voyelle 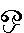 (O) suivie de la consonne
(O) suivie de la consonne  (LLA). Si on utilise le codage par mappage de
police, il devient évident que la recherche, le tri et tout autre traitement
de texte similaire sont compromis à cause de cette ambiguïté, qui n'existe pas
lorsqu'un codage correct est utilisé.
(LLA). Si on utilise le codage par mappage de
police, il devient évident que la recherche, le tri et tout autre traitement
de texte similaire sont compromis à cause de cette ambiguïté, qui n'existe pas
lorsqu'un codage correct est utilisé.La conclusion est on ne peut plus simple : n'utilisez pas <FONT
FACE>, surtout si c'est pour trafiquer l'identité des caractères. Il
existe de meilleurs moyens de publier en plusieurs langues sur le Web, comme en
témoignent nos pages sur la
création d'un site Web multilingue.
Si vous croyez faire avancer la cause d'une langue en fabriquant des polices
et en les utilisant pour publier sur le Web via <FONT FACE>,
pensez-y à deux fois. Assurez-vous plutôt de bien maintenir la distinction entre
octets, caractères et glyphes :

