
The <FONT> element, especially with a FACE attribute, is
one of the worst scourges to have hit the Web in recent times. While it is possible to put
<FONT> to good use, most applications are not advisable, as testified by
this article devoted to
<FONT>. The article points out the bad effects that
<FONT FACE> can have even when used for the purpose it was designed for
(controlling style), but does not address the problems it creates when misused in
multilingual documents; this is what we will discuss here.
Text is normally transfered on the Web - as well as in other Internet applications - as a sequence of coded characters. That is, to each code value corresponds by convention a single character, which a receiving application can interpret and display. There are a number of such character codes, each covering a given character repertoire, normally corresponding to a script.
The point is that if you use <FONT FACE>, and specify a font for a
different script, you are in fact lying to the browser about the identity of the characters
that are supposedly identified by the underlying codes in your computer. If you type
<FONT FACE="some_Greek_font">xyqdwo </FONT>, you will indeed get
Greek, but this is not the proper way to encode Greek text.
There are a number of problems with the above approach. The most evident is that bad things happen if the user looking at your page does not have exactly the font that you specified: he will see the text in his browser's default font, which will not be Greek (unless he is Greek, of course!), whereas he may have a perfectly good Greek font on his system, which could have been used if you had coded the text properly.
This brings to the forefront the problem of font proliferation: the characters (actually
glyphs) in a font are
numbered, the set of glyph-number associations forming what is
known as the coding of the font. But there are a large number of these, even for a given
language or script. If you use simplistic font mapping (which is what
<FONT FACE> does) to encode text, you are at the mercy of the particular
coding of the font you chose. When the guy next door chooses another font, coded differently,
you will have to install his font to display his pages. And then this other
author uses this other font, that other budding webmaster uses that other font, etc... Your
disk is getting full of fonts? No wonder! And you have not even addressed style yet, this
proliferation is just useless redundancy.
And the Webspace has become fragmented, with mutually incomprehensible parts (unless you have all the right fonts), not exactly what the Web was intended for! Just think of the mess if there existed 5 flavours of ASCII, all incompatible, and if users constantly had to convert from one to the other, after guessing which it is.
And what about searching for this Greek (or other) text, using your favorite search engine? Not a chance! You have to know what font the author used even before you look for the text, in order for you to provide the search engine with the "correct" false characters. Even using your browser's search function to look for a word within a page is not likely to give the expected results.
Similarly, a list of Greek (or other, again) words coded by font mapping is not likely to
sort correctly, if you ever want to do that. In fact, any kind of text processing is next
to impossible using that technique. If you are authoring Web pages - and you are if you
use <FONT FACE> - you probably do quite a bit of cut-and-paste. No luck
if the text you are cutting doesn't use the same font as the document you want to paste
into! Time to retype the whole thing; but then, the keyboard layout depends on the font,
doesn't it?
The Internet is about communication. The Web uses HTML as a common document format, but what
about all the other means of communications? HTML is generally not an option, and you will
have to forget about using the HTMLish <FONT FACE> with those. Time to
consider a real character encoding, which will be able to carry your words in plain text,
whatever the medium (mail, news, chat, etc.) HTML is about enriching text with
hyperlinks and embellishments, but the underlying plain text should already have its proper
meaning before HTML markup comes into play. <FONT FACE> prevents that.
The situation gets even hairier when a complex script is involved. What is a complex script?
Well, "simple" scripts are those where there is a one-to-one relationship between characters
and glyphs; the others are complex. Examples of simple scripts are Latin, Cyrillic and Chinese.
Chinese is simple? Characters and glyphs do map one-to-one in Chinese, but for computers it is
complex because there are so many characters; one byte is not enough to encode all of them (by
far!), two or more are required and <FONT FACE> just doesn't work at all.
Same for Japanese and Korean.
In some complex scripts the glyph changes according to the position of the character within a word (initial, medial, final or isolated), as in Arabic. Or there exist compulsory ligatures where two or more characters turn into a single glyph, as in Devânagari (used by the Hindi language). Or one character is displayed as two glyphs that straddle the glyph of another character, as in Tamil.
Additionally:
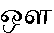 can be seen
as either the vowel (AU), or as the vowel
can be seen
as either the vowel (AU), or as the vowel 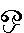 (O) followed by the consonant
(O) followed by the consonant  (LLA). If coded by font mapping, this is obviously very bad for searching, sorting, or other
processing of the text because of the ambiguity, which a proper character encoding would
not have.
(LLA). If coded by font mapping, this is obviously very bad for searching, sorting, or other
processing of the text because of the ambiguity, which a proper character encoding would
not have.The conclusion is very simple: do not use <FONT FACE>, especially to cheat
about the identity of characters. There are better ways to get various languages on the Web,
see our pages about creating your own multilingual
Web site.
If you think you are doing some language community a service by making up fonts and using them as described above to publish on the Web, please think again. Consider instead keeping your bytes, characters and glyphs as separate things:

